Data Engineer (Automation)
Network IT Recruitment
Central Milton Keynes, United Kingdom
2 days ago
Role details
Contract type
Permanent contract Employment type
Full-time (> 32 hours) Working hours
Regular working hours Languages
English Compensation
£ 55KJob location
Central Milton Keynes, United Kingdom
Tech stack
Agile Methodologies
Artificial Intelligence
Data analysis
Azure
Big Data
Cloud Computing
Continuous Integration
Information Engineering
Data Governance
Data Integration
Data Systems
Data Warehousing
Relational Databases
DevOps
Python
Machine Learning
Microsoft SQL Server
Performance Tuning
Scrum
DataOps
SQL Databases
Data Streaming
Data Processing
Data Ingestion
Azure
Large Language Models
Data Strategy
Data Pipelines
Databricks
Job description
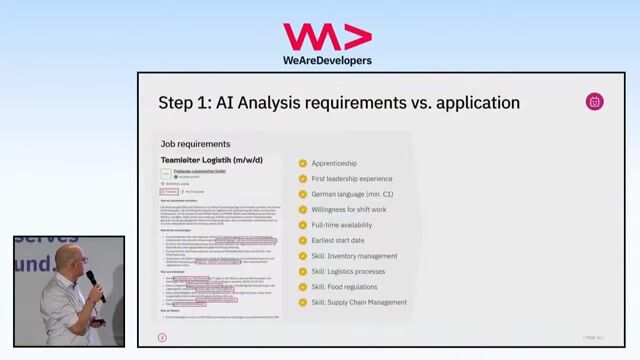
As a Data Automation Engineer, you will take ownership of the delivery, operation, and continuous improvement of automated data pipelines and platform components across Azure and on prem environments. You'll work closely with Data Engineers, Solution Architects, Application Managers, and international teams to ensure data operations are scalable, resilient, and aligned with governance and quality standards., * Designing, building, and maintaining fully automated end to end data pipelines, ensuring secure, reliable data ingestion, transformation, delivery, and documentation.
- Delivering high quality data flows using tools such as Azure Data Factory, Databricks, SQL, and Python, reducing manual intervention through standardisation and automation.
- Identifying and implementing improvements in speed, reliability, and scalability, including opportunities to apply AI supported automation and optimisation.
- Preparing and maintaining high quality datasets and AI ready data models (DWH/Lakehouse) to support analytics, reporting, and machine learning use cases.
- Monitoring and troubleshooting daily data operations, resolving issues following ITIL best practices, and implementing proactive improvements, alerting, and self healing mechanisms.
- Enhancing pipeline performance and observability, improving monitoring, alerting, and automated preventative rules.
- Supporting data governance processes such as data quality, lineage, masking, encryption, archiving, and compliance, with increasing automation maturity.
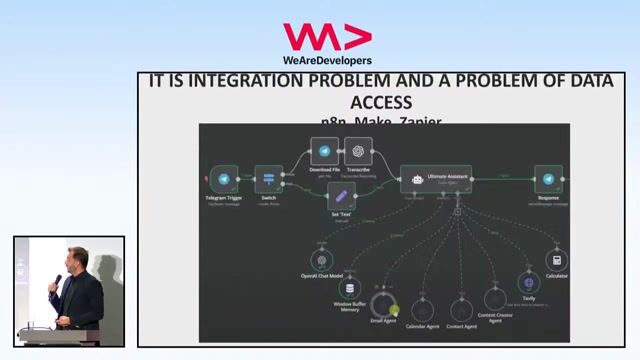
- Contributing to CI/CD processes, orchestration, scheduling, and platform level enhancements to support scalable, AI enabled data foundations.
- Collaborating with cross functional and international teams to align changes, share best practices, and support the execution of the organisation's data strategy.
Requirements
- Proven experience delivering automated end to end data engineering solutions in complex environments.
- Advanced SQL skills, including performance tuning and optimised queries across large datasets to prepare AI ready data.
- Knowledge of Python (or R) for data processing, transformation, or analytics.
- Hands on experience with cloud and on prem data integration tools such as Azure Data Factory and Databricks.
- Strong background in data modelling, data warehousing, and relational database environments (eg, MS SQL Server).
- Experience designing cloud native and on prem data solutions.
- Exposure to AI/ML initiatives, AI enabled automation, and an understanding of LLM concepts and their data workflow applications.
- Experience working in Agile environments (Scrum, Kanban, DevOps).
- Strong analytical, problem solving, and communication skills, with the ability to work effectively across technical and non technical teams.