Don't Change the Partition Count for Kafka Topics!
A well-intentioned infrastructure change silently corrupted our search index. Discover how increasing a Kafka topic's partition count can break your entire data pipeline.
#1about 5 minutes
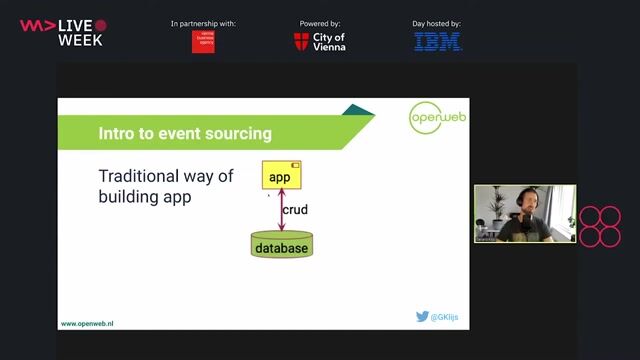
An overview of the data indexing pipeline architecture
The system moves data from a MySQL primary data store to an Elasticsearch search server using a Kafka and Kafka Connect pipeline.
#2about 1 minute
Using Kafka partition offset for optimistic concurrency control
The system leverages the Kafka partition offset as the document version number in Elasticsearch to enable parallel indexing without data consistency issues.
#3about 2 minutes
Investigating a mysterious data deletion failure in production
A bug report about Elasticsearch failing to delete documents, which serves stale data, could not be reproduced in local or testing environments.
#4about 5 minutes
Discovering the offset and version number mismatch
Manual inspection reveals that the document version in Elasticsearch is significantly higher than the new message offset in the Kafka topic for the same key.
#5about 4 minutes
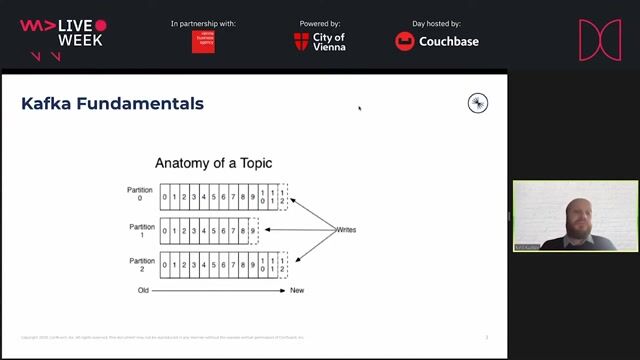
How changing partition count breaks message ordering guarantees
Increasing the Kafka topic's partition count changes the key hashing algorithm, causing new messages for the same key to land in different partitions with lower offsets.
#6about 4 minutes
The solution and key lessons for managing Kafka topics
The fix required a full data re-ingestion into a new Kafka topic, highlighting the lesson to never increase partition count when message ordering is critical.
Related jobs
Jobs that call for the skills explored in this talk.
Dev Digest 134 - Where pixels sing?News and ArticlesWeAreDevelopers LIVE Data and Security Day is on Wednesday, 25/09/2024. Learn about OPC UA Updates, Best Practices for Using GitHub Secrets, Passwordless Web 1.5, Emerging AI Security Risks, Data Privacy in LLMs and get a chance to t...
Daniel Cranney
Dev Digest 201: Don't Stop Thinking, AI Slop vs. OSS Security, Rank ThingsInside last week’s Dev Digest 201 .
🧠 Despite AI you still need to think
🍋 Bitter lessons from building AI products
🤖 AI Slop vs. OSS security
📱 Cloning tap-to-pay on Android
🤑 Saving $500k/year by re-inventing S3
📄 AI reads manuals
🎥 Automating FFM...
Daniel Cranney
Dev Digest 168: Hacking Postgres, Blocking Meta and Fixing CSSInside last week’s Dev Digest 168 .
📊 The state of OpenAI’s GPT models
🤖 20% of Salesforce code written by AI
👩💻 Hacking Postgres
🙅♂️ How to block Meta AI from your Instagram
🔧 How to fix common CSS mistakes
💻 Make your GitHub profile stand out
🥱 ...