How do you decommission a 500,000-line monolith with zero downtime? It starts with migrating the data, not refactoring the code.
#1about 2 minutes
The challenge of a high-traffic monolithic system
The system handles user flows for major brands with one million daily sessions, managing user data and provisioning it to partners.
#2about 3 minutes
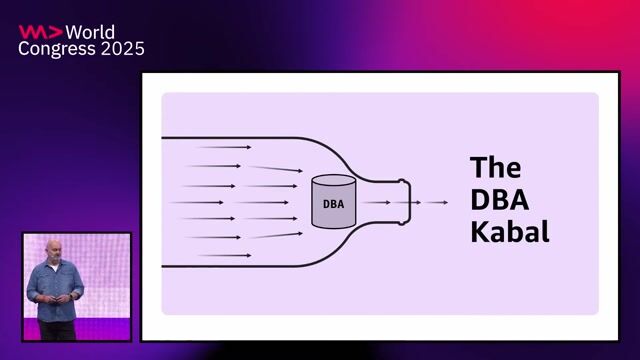
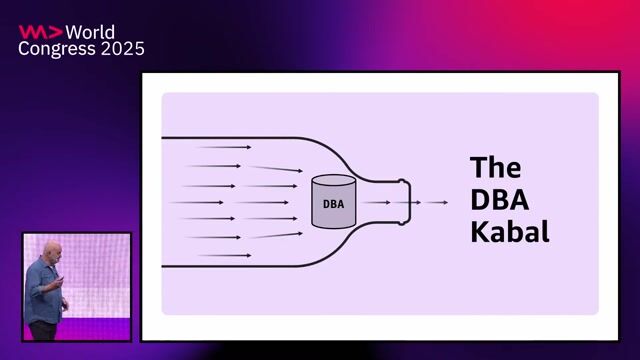
Why the monolith was difficult to maintain
The application's 500,000 lines of code, heavily customized frameworks, and data center limitations made even small changes disproportionately difficult.
#3about 2 minutes
Why the code-first refactoring approach failed
An initial attempt at incremental refactoring and service extraction failed due to tight coupling with the legacy code and a complex data model.
#4about 3 minutes
Adopting a data-first migration strategy
The successful strategy involved migrating data to a new location first, which enabled rebuilding components and drastically simplifying the data model.
#5about 3 minutes
Implementing event-driven data synchronization with AWS
An event-driven pattern using AWS SQS and Lambda was created to sync every data change from the old system to the new database in parallel.
#6about 1 minute
Replacing user flows with a SaaS solution
Instead of rebuilding authentication and authorization, a software as a service (SaaS) solution like Ory was used to leverage expert knowledge and accelerate development.
#7about 1 minute
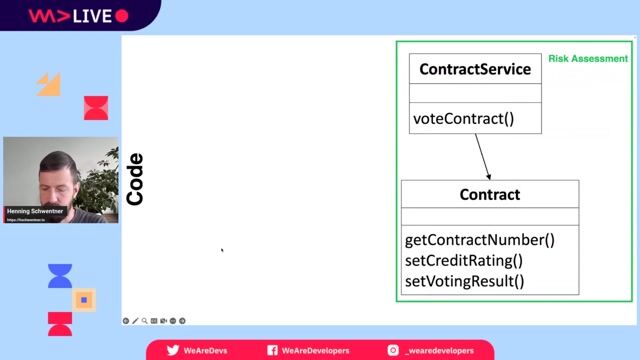
Building and securing the new microservices architecture
Splitting the monolith into microservices allowed for mature, granular control over security, including authentication at the network, path, and field level.
#8about 2 minutes
Executing a zero-downtime switchover process
A phased rollout and parallel systems enabled a switch to the new registration and login flows with zero downtime, changing the single source of truth seamlessly.
#9about 3 minutes
Adopting a modern tech stack for faster development
Using a cloud-native framework like Quarkus and focusing on writing "glue code" between services drastically reduced implementation time and improved maintainability.
#10about 1 minute
Testing against production with continuous deployment
The team tests new components against production services in the pipeline, relying on extensive monitoring, alerting, and a fast, continuous deployment process.
#11about 2 minutes
Balancing consistency with rebuilding over refactoring
Maintaining a consistent tech stack is a trade-off with innovation, and for complex legacy systems, rebuilding components is often more effective than refactoring.
Related jobs
Jobs that call for the skills explored in this talk.
Why Attend a Developer Event?Modern software engineering moves too fast for documentation alone. Attending a world-class event is about shifting from tactical execution to strategic leadership.
Skill Diversification: Break out of your specific tech stack to see how the industry...