Building Blocks of RAG: From Understanding to Implementation
How can you stop LLMs from hallucinating? Discover Retrieval-Augmented Generation, the efficient way to ground models in your own data.
#1about 2 minutes
Tech stack for building a RAG application
The core technologies used for the RAG implementation include Python, Groq for LLM inference, LangChain as a framework, FAISS for the vector database, and Streamlit for the UI.
#2about 1 minute
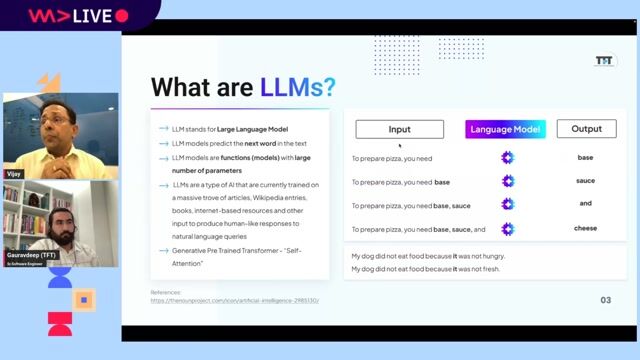
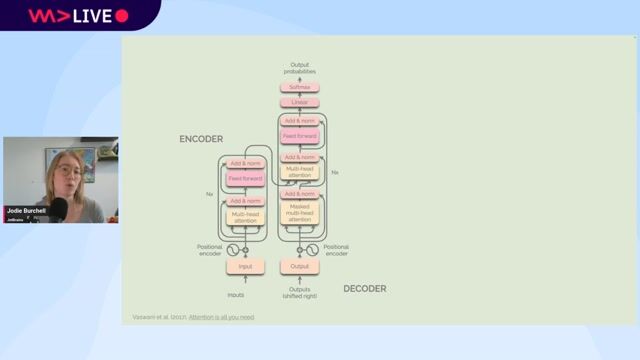
Understanding the fundamentals of large language models
Large language models are deep learning models pre-trained on vast data, using a transformer architecture with an encoder and decoder to understand and generate human-like text.
#3about 3 minutes
The rapid evolution and adoption of LLMs
The journey of LLMs has accelerated from the 2022 ChatGPT launch to widespread experimentation in 2023 and enterprise production adoption in 2024.
#4about 2 minutes
Key challenges of LLMs like hallucination
Standard LLMs face significant challenges including hallucination, unverifiable sources, and knowledge cutoffs that limit their reliability for enterprise use.
#5about 1 minute
How RAG solves LLM limitations
Retrieval-Augmented Generation addresses LLM weaknesses by retrieving relevant, up-to-date information from external data sources to provide accurate and verifiable responses.
#6about 4 minutes
The data ingestion and processing pipeline
The first stage of RAG involves loading documents, splitting them into manageable chunks, converting those chunks into numerical embeddings, and storing them in a vector database.
#7about 2 minutes
The retrieval and generation process
The second stage of RAG handles user queries by retrieving relevant chunks from the vector store, constructing a detailed prompt with that context, and sending it to the LLM for generation.
#8about 4 minutes
Visualizing the end-to-end RAG architecture
A complete RAG system processes a user's query by creating an embedding, finding similar document chunks in the vector DB, and feeding both the query and context to an LLM to generate a grounded response.
#9about 5 minutes
Demo of a RAG-powered document chatbot
A live demonstration shows a Streamlit application that allows users to upload a PDF and ask questions, receiving answers grounded in the document's content.
#10about 2 minutes
Summary and deploying RAG solutions
A recap of the RAG process is provided, along with considerations for deploying these solutions in enterprise environments using managed cloud services or open-source models.
Related jobs
Jobs that call for the skills explored in this talk.
The Web We Broke (And Why AI Agents Are Paying the Price) - AgentCon BerlinThis is the accompanying post to the talk Chris Heilmann gave at AgentCon in Berlin on 19/05/2026, you can also see the slides and listen to it in this screencast:
Thirty years of developer shortcuts, bloated JavaScript, and inaccessible HTML have l...
Daniel Cranney, Chris Heilmann
Dev Digest 215: Agent Memory, JS2026, Googlebot Analysis & Canvas❤️HTMLInside last week’s Dev Digest 215 .
🗿 Make AI talk like a caveman
🧠 A guide to context engineering for LLMs
🤖 Simon Willison on agentic engineering
🔐 Axios supply chain attack post mortem
🛡️ Designing AI agents to resist prompt injection
🎨 HTML in c...