Reducing LLM Calls with Vector Search Patterns - Raphael De Lio (Redis)
Large context windows aren't the answer. Learn three vector search patterns to slash your LLM costs and latency.
#1about 3 minutes
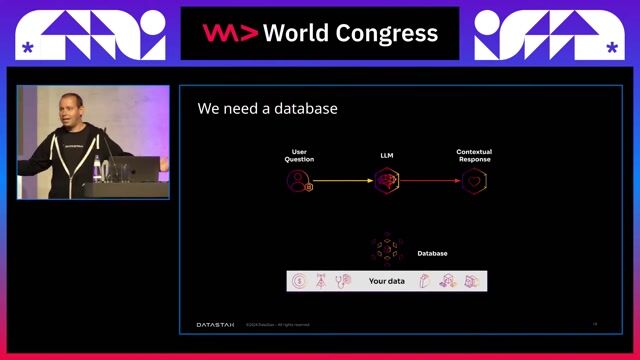
The hidden costs of large LLM context windows
Large context windows in models like GPT-5 seem to eliminate the need for RAG, but the high token cost makes this approach expensive and unscalable for every request.
#2about 3 minutes
A brief introduction to vectors and vector search
Text is converted into numerical vector embeddings that capture its semantic meaning, allowing computers to efficiently calculate the similarity between different phrases or documents.
#3about 9 minutes
How to classify text using a vector database
Instead of using a costly LLM for every classification task, you can use a vector database to match new text against pre-embedded reference examples for a specific label.
#4about 5 minutes
Using semantic routing for efficient tool calling
By matching user prompts against pre-defined reference phrases for each tool, you can directly trigger the correct function without an initial, expensive LLM call.
#5about 5 minutes
Reducing latency and cost with semantic caching
Semantic caching stores LLM responses and serves them for new, semantically similar prompts, which avoids re-computation and significantly reduces both cost and latency.
#6about 7 minutes
Strategies for optimizing vector search accuracy
Improve the accuracy of vector search patterns through techniques like self-improvement, a hybrid approach that falls back to an LLM, and chunking complex prompts into smaller clauses.
#7about 3 minutes
Addressing advanced challenges in semantic caching
Mitigate common caching pitfalls, like misinterpreting negative prompts, by using specialized embedding models and combining semantic routing with caching to avoid caching certain types of queries.
Related jobs
Jobs that call for the skills explored in this talk.
Dev Digest 158: Super Mario AI 🔑 API keys in LLMs 🤙🏾 Vibe CodingInside last week’s Dev Digest 158 .
🎮 Testing AI with Super Mario
🤖 Hallucinating AI is the least of our worries
🔑 Deepseek’s training data contains 12,000 live API keys and passwords
💀 Hanging up on Skype
📃 Rules for Developing Safety Critical Code...
Andrew Brookins, Raphael De Lio
Introducing Redis Agent Memory ServerOne of the biggest challenges AI engineers face today is memory management. Large language models are stateless. Every request must carry all the information the model needs to respond well.
This is the art of context engineering. Building agents is ...
Dev Digest 138 - Are you secure about this?Hello there! This is the 2nd "out of the can" edition of 3 as I am on vacation in Greece eating lovely things on the beach. So, fewer news, but lots of great resources. Many around the topic of security. Enjoy! News and ArticlesGoogle Pixel phones t...
From learning to earning
Jobs that call for the skills explored in this talk.